This the multi-page printable view of this section. Click here to print.
Kubernetes
- 1: Recommended Agenda
- 2: Introduction to Kubernetes
- 3: Deploying Your First Nginx Pod
- 4: Deploying Your First Kubernetes Service
- 5: Deploying Your First Nginx Deployment
- 6: Deploying Your First DaemonSet
- 7: Deploying Your First Nginx ReplicaSet
- 8: Understand Kubernetes Scheduling
- 9: Deploying Your First Ingress Deployment
1 - Recommended Agenda
2 - Introduction to Kubernetes
What is Kubernetes?
Kubernetes (commonly referred to as K8s) is an orchestration engine for container technologies such as Docker and rkt that is taking over the DevOps scene in the last couple of years. It is already available on Azure and Google Cloud as a managed service.
Kubernetes can speed up the development process by making easy, automated deployments, updates (rolling-update) and by managing our apps and services with almost zero downtime. It also provides self-healing. Kubernetes can detect and restart services when a process crashes inside the container. Kubernetes is originally developed by Google, it is open-sourced since its launch and managed by a large community of contributors.
Any developer can package up applications and deploy them on Kubernetes with basic Docker knowledge.
What is K8s made up of?
Kubectl:
- A CLI tool for Kubernetes.
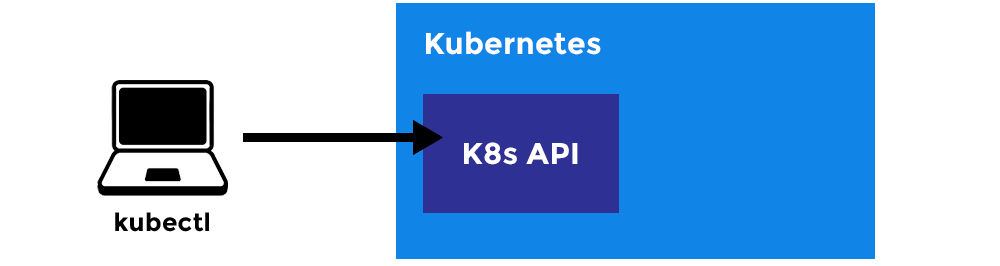
Master Node:
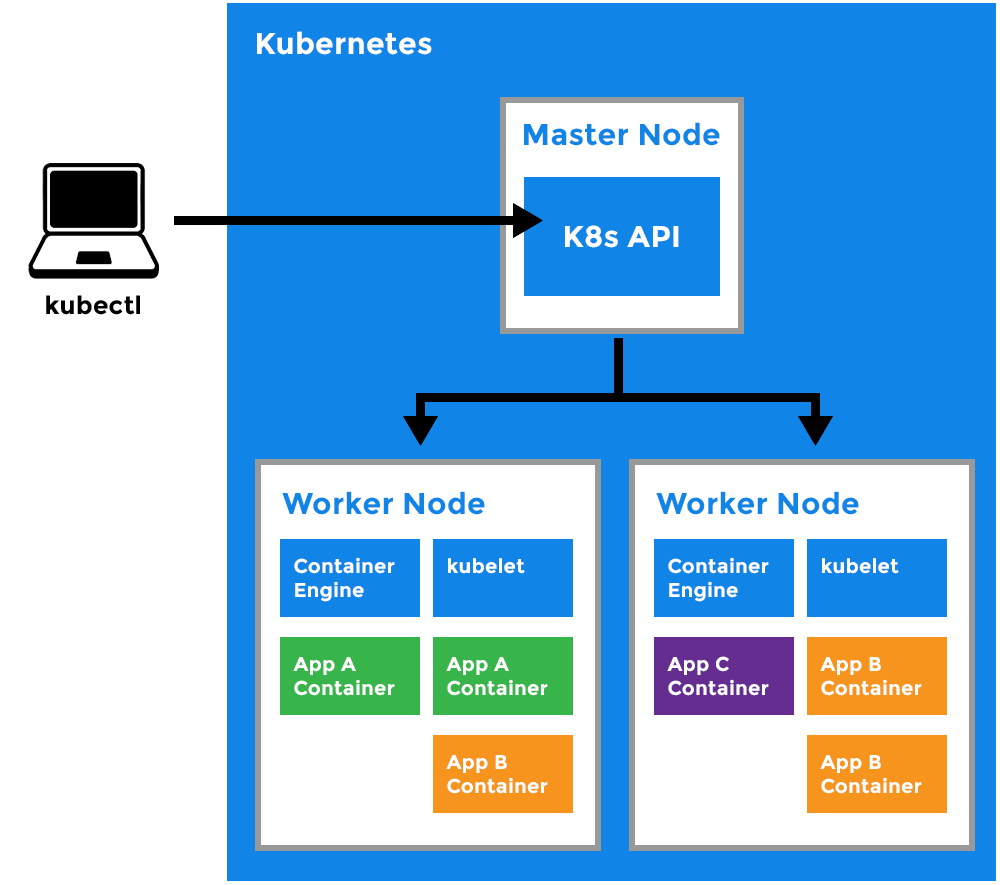
- The main machine that controls the nodes.
- Main entrypoint for all administrative tasks.
- It handles the orchestration of the worker nodes.
Worker Node
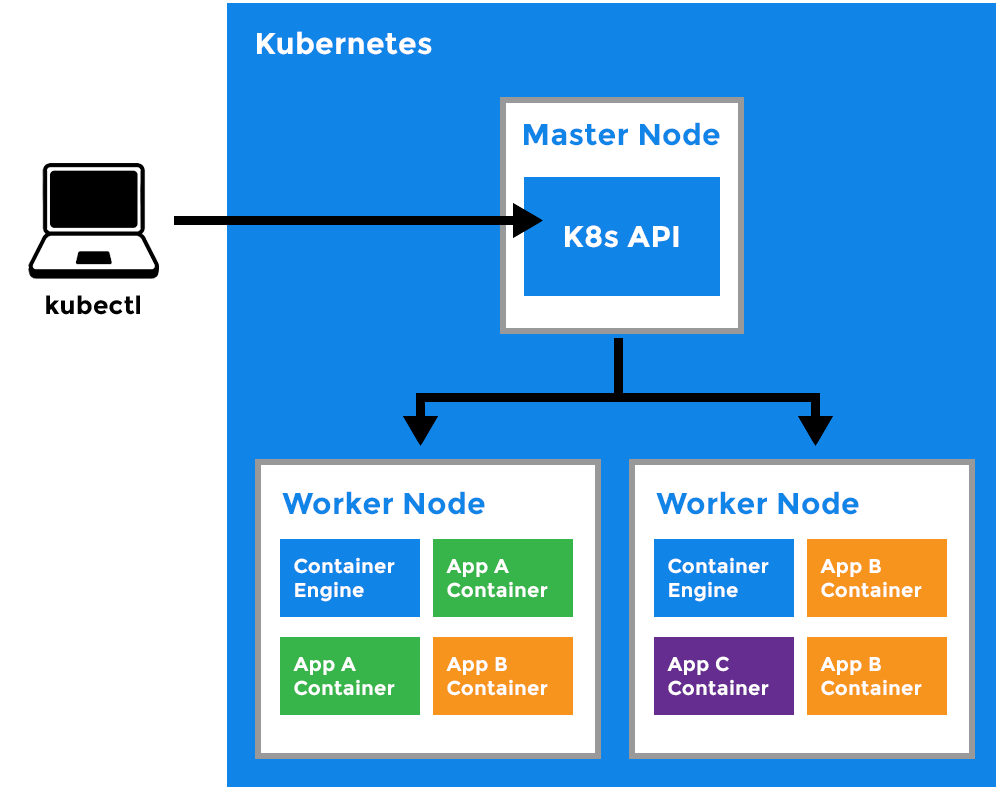
- It is a worker machine in Kubernetes (used to be known as minion).
- This machine performs the requested tasks. Each Node is controlled by the Master Node.
- Runs pods (that have containers inside them).
- This is where the Docker engine runs and takes care of downloading images and starting containers.
Kubelet
- Primary node agent.
- Ensures that containers are running and healthy.
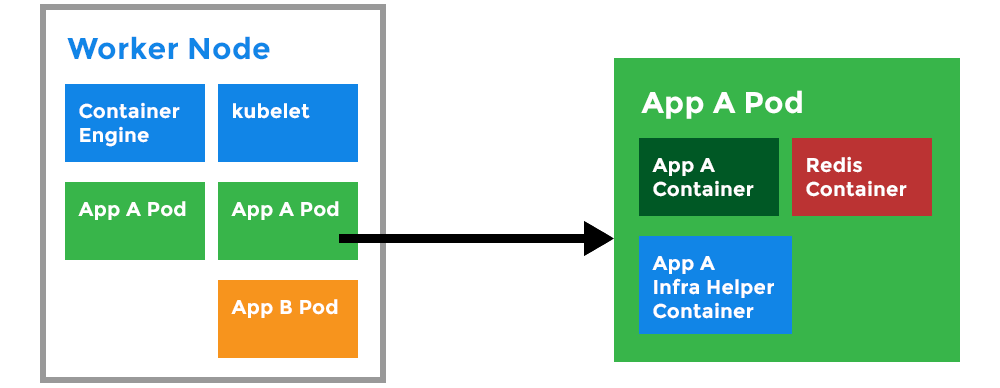
Kubernetes Pod:
- A Pod can host multiple containers and storage volumes.
- Pods are instances of Deployments (see Deployment).
- One Deployment can have multiple pods.
- With Horizontal Pod Autoscaling, Pods of a Deployment can be automatically started and halted based on CPU usage.
- Containers within the same pod have access to shared volumes.
- Each Pod has its unique IP Address within the cluster.
- Pods are up and running until someone (or a controller) destroys them.
- Any data saved inside the Pod will disappear without a persistent storage.
Deployment:
- A deployment is a blueprint for the Pods to be created (see Pod).
- Handles update of its respective Pods.
- A deployment will create a Pod by its spec from the template.
- Their target is to keep the Pods running and update them (with rolling-update) in a more controlled way.
- Pod(s) resource usage can be specified in the deployment.
- Deployment can scale up replicas of Pods.
- kubernetes-deployment.
.png)
Secret:
- A Secret is an object, where we can store sensitive informations like usernames and passwords.
- In the secret files, values are base64 encoded.
- To use a secret, we need to refer to the secret in our Pod.
- Or we can put it inside a volume and mount that to the container.
- Secrets are not encrypted by default. For encryption we need to create an EncryptionConfig.
- You can read more about encryption here
Service:
- A service is responsible for making our Pods discoverable inside the network or exposing them to the internet.
- A Service identifies Pods by its LabelSelector.
- There are 3 types of services:.
ClusterIP:
- The deployment is only visible inside the cluster.
- The deployment gets an internal ClusterIP assigned to it.
- Traffic is load balanced between the Pods of the deployment.
Node Port:
- The deployment is visible inside the cluster.
- The deployment is bound to a port of the Master Node.
- Each Node will proxy that port to your Service.
- The service is available at http(s)://
- Traffic is load balanced between the Pods of the deployment.
Load Balancer:
- The deployment gets a Public IP address assigned.
- The service is available at http(s)://
:80 - Traffic is load balanced between the Pods of the deployment.
Credits:
3 - Deploying Your First Nginx Pod
Deploying Your First Nginx Pod
What are K8s Pods?
- Kubernetes pods are the foundational unit for all higher Kubernetes objects.
- A pod hosts one or more containers.
- It can be created using either a command or a YAML/JSON file.
- Use
kubectlto create pods, view the running ones, modify their configuration, or terminate them. Kuberbetes will attempt to restart a failing pod by default. - If the pod fails to start indefinitely, we can use the
kubectl describecommand to know what went wrong.
Why does Kubernetes use a Pod as the smallest deployable unit, and not a single container?
While it would seem simpler to just deploy a single container directly, there are good reasons to add a layer of abstraction represented by the Pod. A container is an existing entity, which refers to a specific thing. That specific thing might be a Docker container, but it might also be a rkt container, or a VM managed by Virtlet. Each of these has different requirements.
What’s more, to manage a container, Kubernetes needs additional information, such as a restart policy, which defines what to do with a container when it terminates, or a liveness probe, which defines an action to detect if a process in a container is still alive from the application’s perspective, such as a web server responding to HTTP requests.
Instead of overloading the existing “thing” with additional properties, Kubernetes architects have decided to use a new entity, the Pod, that logically contains (wraps) one or more containers that should be managed as a single entity.
Why does Kubernetes allow more than one container in a Pod?
Containers in a Pod run on a “logical host”; they use the same network namespace (in other words, the same IP address and port space), and the same IPC namespace. They can also use shared volumes. These properties make it possible for these containers to efficiently communicate, ensuring data locality. Also, Pods enable you to manage several tightly coupled application containers as a single unit.
So if an application needs several containers running on the same host, why not just make a single container with everything you need? Well first, you’re likely to violate the “one process per container” principle. This is important because with multiple processes in the same container it is harder to troubleshoot the container. That is because logs from different processes will be mixed together and it is harder manage the processes lifecycle. For example to take care of “zombie” processes when their parent process dies. Second, using several containers for an application is simpler, more transparent, and enables decoupling software dependencies. Also, more granular containers can be reused between teams.
Pre-requisite:
Steps
kubectl apply -f pods01.yaml
Viewing Your Pods
kubectl get pods
Which Node Is This Pod Running On?
kubectl get pods -o wide
$ kubectl describe po webserver
Name: webserver
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: gke-standard-cluster-1-default-pool-78257330-5hs8/10.128.0.3
Start Time: Thu, 28 Nov 2019 13:02:19 +0530
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"webserver","namespace":"default"},"spec":{"containers":[{"image":"ngi...
kubernetes.io/limit-ranger: LimitRanger plugin set: cpu request for container webserver
Status: Running
IP: 10.8.0.3
Containers:
webserver:
Container ID: docker://ff06c3e6877724ec706485374936ac6163aff10822246a40093eb82b9113189c
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:189cce606b29fb2a33ebc2fcecfa8e33b0b99740da4737133cdbcee92f3aba0a
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 28 Nov 2019 13:02:25 +0530
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-mpxxg (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-mpxxg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-mpxxg
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m54s default-scheduler Successfully assigned default/webserver to gke-standard-cluster-1-default-pool-78257330-5hs8
Normal Pulling 2m53s kubelet, gke-standard-cluster-1-default-pool-78257330-5hs8 pulling image "nginx:latest"
Normal Pulled 2m50s kubelet, gke-standard-cluster-1-default-pool-78257330-5hs8 Successfully pulled image "nginx:latest"
Normal Created 2m48s kubelet, gke-standard-cluster-1-default-pool-78257330-5hs8 Created container
Normal Started 2m48s kubelet, gke-standard-cluster-1-default-pool-78257330-5hs8 Started container
Output in JSON
$ kubectl get pods -o json
{
"apiVersion": "v1",
"items": [
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{},\"name\":\"webserver\",\"namespace\":\"default\"},\"spec\":{\"con
tainers\":[{\"image\":\"nginx:latest\",\"name\":\"webserver\",\"ports\":[{\"containerPort\":80}]}]}}\n",
"kubernetes.io/limit-ranger": "LimitRanger plugin set: cpu request for container webserver"
},
"creationTimestamp": "2019-11-28T08:48:28Z",
"name": "webserver",
"namespace": "default",
"resourceVersion": "20080",
"selfLink": "/api/v1/namespaces/default/pods/webserver",
"uid": "d8e0b56b-11bb-11ea-a1bf-42010a800006"
},
"spec": {
"containers": [
{
"image": "nginx:latest",
"imagePullPolicy": "Always",
"name": "webserver",
"ports": [
{
"containerPort": 80,
"protocol": "TCP"
}
],
"resources": {
"requests": {
"cpu": "100m"
}
},
"terminationMessagePath": "/dev/termination-log",
"terminationMessagePolicy": "File",
Executing Commands Against Pods
$ kubectl exec -it webserver -- /bin/bash
root@webserver:/#
root@webserver:/# cat /etc/os-release
PRETTY_NAME="Debian GNU/Linux 10 (buster)"
NAME="Debian GNU/Linux"
VERSION_ID="10"
VERSION="10 (buster)"
VERSION_CODENAME=buster
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
Please exit from the shell (/bin/bash) session.
root@webserver:/# exit
Deleting the Pod
$ kubectl delete -f pods01.yaml
pod "webserver" deleted
$ kubectl get po -o wide
No resources found.
Get logs of Pod
$ kubectl logs webserver
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
Ading a 2nd container to a Pod
In the microservices architecture, each module should live in its own space and communicate with other modules following a set of rules. But, sometimes we need to deviate a little from this principle. Suppose you have an Nginx web server running and we need to analyze its web logs in real-time. The logs we need to parse are obtained from GET requests to the web server. The developers created a log watcher application that will do this job and they built a container for it. In typical conditions, you’d have a pod for Nginx and another for the log watcher. However, we need to eliminate any network latency so that the watcher can analyze logs the moment they are available. A solution for this is to place both containers on the same pod.
Having both containers on the same pod allows them to communicate through the loopback interface (ifconfig lo) as if they were two processes running on the same host. They also share the same storage volume.
Let us see how a pod can host more than one container. Let’s take a look to the pods02.yaml file. It contains the following lines:
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: webserver
image: nginx:latest
ports:
- containerPort: 80
- name: webwatcher
image: afakharany/watcher:latest
Run the following command:
$ kubectl apply -f pods02.yaml
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
webserver 0/2 ContainerCreating 0 13s <none> gke-standard-cluster-1-default-pool-78257330-5hs8 <none> <none>
$ kubectl get po,svc,deploy
NAME READY STATUS RESTARTS AGE
pod/webserver 2/2 Running 0 3m6s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.12.0.1 <none> 443/TCP 107m
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
webserver 2/2 Running 0 3m37s 10.8.0.5 gke-standard-cluster-1-default-pool-78257330-5hs8 <none> <none>
How to verify 2 containers are running inside a Pod?
$ kubectl describe po
Containers:
webserver:
Container ID: docker://0564fcb88f7c329610e7da24cba9de6555c0183814cf517e55d2816c6539b829
Image: nginx:latest
Image ID: docker-pullable://nginx@sha256:36b77d8bb27ffca25c7f6f53cadd059aca2747d46fb6ef34064e31727325784e
Port: 80/TCP
State: Running
Started: Wed, 08 Jan 2020 13:21:57 +0530
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-xhgmm (ro)
webwatcher:
Container ID: docker://4cebbb220f7f9695f4d6492509e58152ba661f3ab8f4b5d0a7adec6c61bdde26
Image: afakharany/watcher:latest
Image ID: docker-pullable://afakharany/watcher@sha256:43d1b12bb4ce6e549e85447678a28a8e7b9d4fc398938a6f3e57d2908a9b7d80
Port: <none>
State: Running
Started: Wed, 08 Jan 2020 13:22:26 +0530
Ready: True
Restart Count: 0
Requests:
Since we have two containers in a pod, we will need to use the -c option with kubectl when we need to address a specific container. For example:
$ kubectl exec -it webserver -c webwatcher -- /bin/bash
root@webserver:/# cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.8.0.5 webserver
Please exit from the shell (/bin/bash) session.
root@webserver:/# exit
Cleaning up
kubectl delete -f pods02.yaml
Example of Multi-Container Pod
Let’s talk about communication between containers in a Pod. Having multiple containers in a single Pod makes it relatively straightforward for them to communicate with each other. They can do this using several different methods.
Use Cases for Multi-Container Pods
The primary purpose of a multi-container Pod is to support co-located, co-managed helper processes for a primary application. There are some general patterns for using helper processes in Pods:
Sidecar containers help the main container. Some examples include log or data change watchers, monitoring adapters, and so on. A log watcher, for example, can be built once by a different team and reused across different applications. Another example of a sidecar container is a file or data loader that generates data for the main container.
Proxies, bridges, and adapters connect the main container with the external world. For example, Apache HTTP server or nginx can serve static files. It can also act as a reverse proxy to a web application in the main container to log and limit HTTP requests. Another example is a helper container that re-routes requests from the main container to the external world. This makes it possible for the main container to connect to the localhost to access, for example, an external database, but without any service discovery.
Shared volumes in a Kubernetes Pod
In Kubernetes, you can use a shared Kubernetes Volume as a simple and efficient way to share data between containers in a Pod. For most cases, it is sufficient to use a directory on the host that is shared with all containers within a Pod.
Kubernetes Volumes enables data to survive container restarts, but these volumes have the same lifetime as the Pod. That means that the volume (and the data it holds) exists exactly as long as that Pod exists. If that Pod is deleted for any reason, even if an identical replacement is created, the shared Volume is also destroyed and created anew.
A standard use case for a multi-container Pod with a shared Volume is when one container writes logs or other files to the shared directory, and the other container reads from the shared directory. For example, we can create a Pod like so (pods03.yaml):
In this file (pods03.yaml) a volume named html has been defined. Its type is emptyDir, which means that the volume is first created when a Pod is assigned to a node, and exists as long as that Pod is running on that node. As the name says, it is initially empty. The 1st container runs nginx server and has the shared volume mounted to the directory /usr/share/nginx/html. The 2nd container uses the Debian image and has the shared volume mounted to the directory /html. Every second, the 2nd container adds the current date and time into the index.html file, which is located in the shared volume. When the user makes an HTTP request to the Pod, the Nginx server reads this file and transfers it back to the user in response to the request.
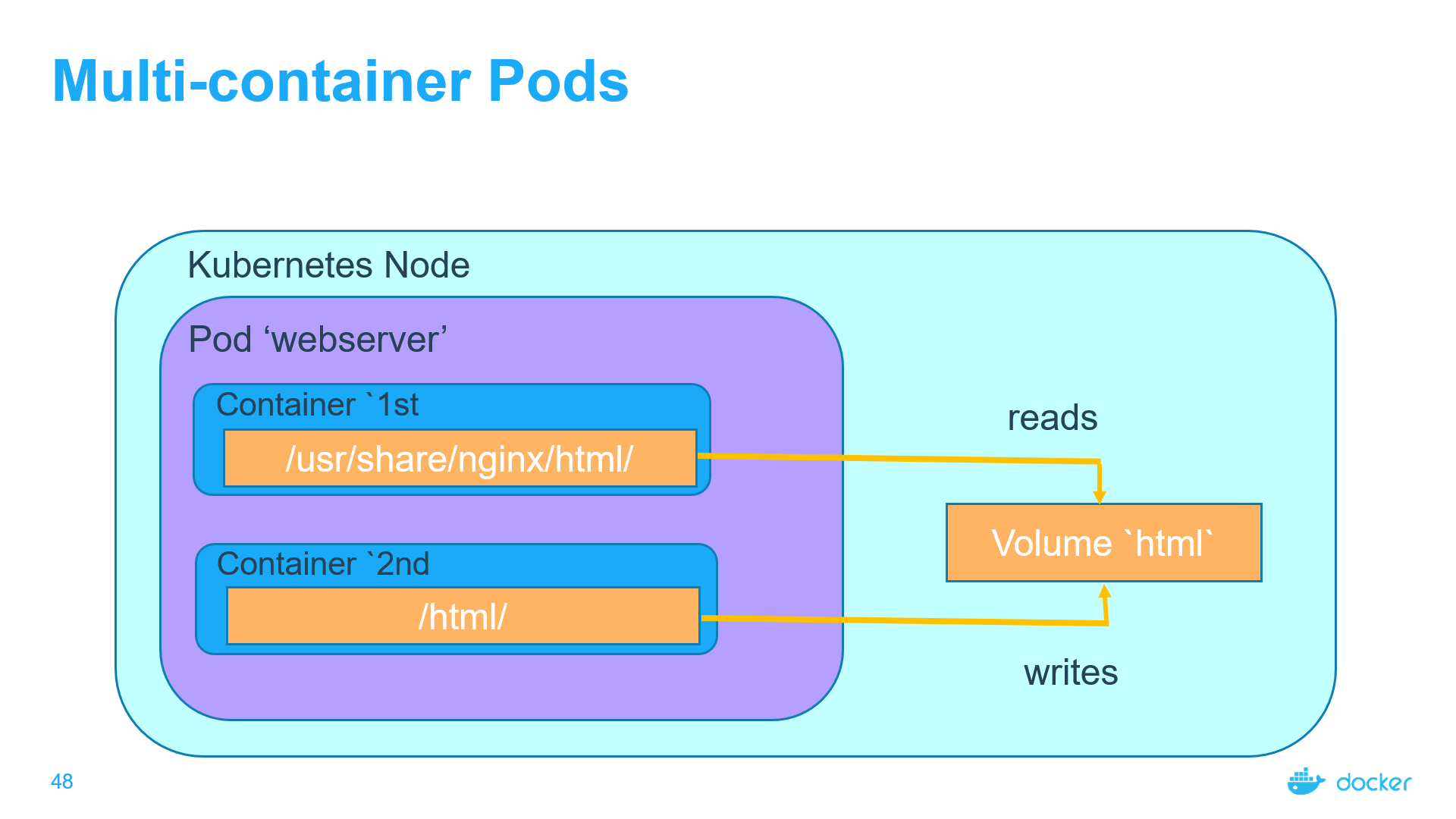
kubectl apply -f pods03.yaml
[Captains-Bay]🚩 > kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/mc1 2/2 Running 0 11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kubernetes ClusterIP 10.15.240.1 <none> 443/TCP 1h
[Captains-Bay]🚩 > kubectl describe po mc1
Name: mc1
Namespace: default
Node: gke-k8s-lab1-default-pool-fd9ef5ad-pc18/10.140.0.16
Start Time: Wed, 08 Jan 2020 14:29:08 +0530
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"mc1","namespace":"default"},"spec":{"containers":[{"image":"nginx","name":"1st","v...
kubernetes.io/limit-ranger=LimitRanger plugin set: cpu request for container 1st; cpu request for container 2nd
Status: Running
IP: 10.12.2.6
Containers:
1st:
Container ID: docker://b08eb646f90f981cd36c605bf8fead3ca62178c7863598fd4558cb026ed067dd
Image: nginx
Image ID: docker-pullable://nginx@sha256:36b77d8bb27ffca25c7f6f53cadd059aca2747d46fb6ef34064e31727325784e
Port: <none>
State: Running
Started: Wed, 08 Jan 2020 14:29:09 +0530
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Environment: <none>
Mounts:
/usr/share/nginx/html from html (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-xhgmm (ro)
2nd:
Container ID: docker://63180b4128d477810d6062342f4b8e499de684ffd69ad245c29118e1661eafcb
Image: debian
Image ID: docker-pullable://debian@sha256:c99ed5d068d4f7ff36c7a6f31810defebecca3a92267fefbe0e0cf2d9639115a
Port: <none>
Command:
/bin/sh
-c
Args:
while true; do date >> /html/index.html; sleep 1; done
State: Running
Started: Wed, 08 Jan 2020 14:29:14 +0530
Ready: True
Restart Count: 0
Requests:
cpu: 100m
Environment: <none>
Mounts:
/html from html (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-xhgmm (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
html:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
default-token-xhgmm:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-xhgmm
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 18s default-scheduler Successfully assigned default/mc1 to gke-k8s-lab1-default-pool-fd9ef5ad-pc18
Normal Pulling 17s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 pulling image "nginx"
Normal Pulled 17s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Successfully pulled image "nginx"
Normal Created 17s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Created container
Normal Started 17s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Started container
Normal Pulling 17s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 pulling image "debian"
Normal Pulled 13s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Successfully pulled image "debian"
Normal Created 12s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Created container
Normal Started 12s kubelet, gke-k8s-lab1-default-pool-fd9ef5ad-pc18 Started container
$ kubectl exec mc1 -c 1st -- /bin/cat /usr/share/nginx/html/index.html
...
Wed Jan 8 08:59:14 UTC 2020
Wed Jan 8 08:59:15 UTC 2020
Wed Jan 8 08:59:16 UTC 2020
$ kubectl exec mc1 -c 2nd -- /bin/cat /html/index.html
...
Wed Jan 8 08:59:14 UTC 2020
Wed Jan 8 08:59:15 UTC 2020
Wed Jan 8 08:59:16 UTC 2020
Cleaning Up
kubectl delete -f pods03.yaml
4 - Deploying Your First Kubernetes Service
What are Kubernetes Services?
Say, you have pods running nginx in a flat, cluster wide, address space. In theory, you could talk to these pods directly, but what happens when a node dies? The pods die with it, and the Deployment will create new ones, with different IPs. This is the problem a Service solves.
Kubernetes Pods are mortal. They are born and when they die, they are not resurrected. If you use a Deployment to run your app, it can create and destroy Pods dynamically. Each Pod gets its own IP address, however in a Deployment, the set of Pods running in one moment in time could be different from the set of Pods running that application a moment later.
This leads to a problem: if some set of Pods (call them “backends”) provides functionality to other Pods (call them “frontends”) inside your cluster, how do the frontends find out and keep track of which IP address to connect to, so that the frontend can use the backend part of the workload?
Enter Services
A Kubernetes Service is an abstraction which defines a logical set of Pods running somewhere in your cluster, that all provide the same functionality. When created, each Service is assigned a unique IP address (also called clusterIP). This address is tied to the lifespan of the Service, and will not change while the Service is alive. Pods can be configured to talk to the Service, and know that communication to the Service will be automatically load-balanced out to some pod that is a member of the Service.
Deploying a Kubernetes Service
Like all other Kubernetes objects, a Service can be defined using a YAML or JSON file that contains the necessary definitions (they can also be created using just the command line, but this is not the recommended practice). Let’s create a NodeJS service definition. It may look like the following:
$ kubectl apply -f nginx-svc.yaml
This specification will create a Service which targets TCP port 80 on any Pod with the run: my-nginx label, and expose it on an abstracted Service port (targetPort: is the port the container accepts traffic on, port: is the abstracted Service port, which can be any port other pods use to access the Service). View Service API object to see the list of supported fields in service definition. Check your Service
$ kubectl get svc my-nginx
As mentioned previously, a Service is backed by a group of Pods. These Pods are exposed through endpoints. The Service’s selector will be evaluated continuously and the results will be POSTed to an Endpoints object also named my-nginx. When a Pod dies, it is automatically removed from the endpoints, and new Pods matching the Service’s selector will automatically get added to the endpoints. Check the endpoints, and note that the IPs are the same as the Pods created in the first step:
$ kubectl describe svc my-nginx
You should now be able to curl the nginx Service on
Accessing the Service
Kubernetes supports 2 primary modes of finding a Service - environment variables and DNS
Environment Variables
When a Pod runs on a Node, the kubelet adds a set of environment variables for each active Service. This introduces an ordering problem. To see why, inspect the environment of your running nginx Pods (your Pod name will be different):
$ kubectl exec my-nginx-3800858182-jr4a2 -- printenv | grep SERVICE
KUBERNETES_SERVICE_HOST=10.0.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
Note there’s no mention of your Service. This is because you created the replicas before the Service. Another disadvantage of doing this is that the scheduler might put both Pods on the same machine, which will take your entire Service down if it dies. We can do this the right way by killing the 2 Pods and waiting for the Deployment to recreate them. This time around the Service exists before the replicas. This will give you scheduler-level Service spreading of your Pods (provided all your nodes have equal capacity), as well as the right environment variables:
$ kubectl scale deployment my-nginx --replicas=0; kubectl scale deployment my-nginx --replicas=2;
$ kubectl get pods -l run=my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-e9ihh 1/1 Running 0 5s 10.244.2.7 kubernetes-minion-ljyd
my-nginx-3800858182-j4rm4 1/1 Running 0 5s 10.244.3.8 kubernetes-minion-905m
You may notice that the pods have different names, since they are killed and recreated.
$ kubectl exec my-nginx-3800858182-e9ihh -- printenv | grep SERVICE
KUBERNETES_SERVICE_PORT=443
MY_NGINX_SERVICE_HOST=10.0.162.149
KUBERNETES_SERVICE_HOST=10.0.0.1
MY_NGINX_SERVICE_PORT=80
KUBERNETES_SERVICE_PORT_HTTPS=443
DNS
Kubernetes offers a DNS cluster addon Service that automatically assigns dns names to other Services. You can check if it’s running on your cluster:
$ kubectl get services kube-dns --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 8m
The rest of this section will assume you have a Service with a long lived IP (my-nginx), and a DNS server that has assigned a name to that IP. Here we use the CoreDNS cluster addon (application name kube-dns), so you can talk to the Service from any pod in your cluster using standard methods (e.g. gethostbyname()). If CoreDNS isn’t running, you can enable it referring to the CoreDNS README or Installing CoreDNS. Let’s run another curl application to test this:
$ kubectl run curl --image=radial/busyboxplus:curl -i --tty
Waiting for pod default/curl-131556218-9fnch to be running, status is Pending, pod ready: false
Hit enter for command prompt
Then, hit enter and run nslookup my-nginx:
$ nslookup my-nginx
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: my-nginx
Address 1: 10.0.162.149
Exposing the Service
For some parts of your applications you may want to expose a Service onto an external IP address. Kubernetes supports two ways of doing this: NodePorts and LoadBalancers. The Service created in the last section already used NodePort, so your nginx HTTPS replica is ready to serve traffic on the internet if your node has a public IP.
$ kubectl get svc my-nginx -o yaml | grep nodePort -C 5
uid: 07191fb3-f61a-11e5-8ae5-42010af00002
spec:
clusterIP: 10.0.162.149
ports:
- name: http
nodePort: 31704
port: 8080
protocol: TCP
targetPort: 80
- name: https
nodePort: 32453
port: 443
protocol: TCP
targetPort: 443
selector:
run: my-nginx
$ kubectl get nodes -o yaml | grep ExternalIP -C 1
- address: 104.197.41.11
type: ExternalIP
allocatable:
--
- address: 23.251.152.56
type: ExternalIP
allocatable:
...
$ curl https://<EXTERNAL-IP>:<NODE-PORT> -k
...
<h1>Welcome to nginx!</h1>
Let’s now recreate the Service to use a cloud load balancer, just change the Type of my-nginx Service from NodePort to LoadBalancer:
$ kubectl edit svc my-nginx
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 162.222.184.144 80/TCP,81/TCP,82/TCP 21s
curl https://<EXTERNAL-IP> -k
...
<title>Welcome to nginx!</title>
The IP address in the EXTERNAL-IP column is the one that is available on the public internet. The CLUSTER-IP is only available inside your cluster/private cloud network.
Note that on AWS, type LoadBalancer creates an ELB, which uses a (long) hostname, not an IP. It’s too long to fit in the standard kubectl get svc output, in fact, so you’ll need to do kubectl describe service my-nginx to see it. You’ll see something like this:
$ kubectl describe service my-nginx
...
LoadBalancer Ingress: a320587ffd19711e5a37606cf4a74574-1142138393.us-east-1.elb.amazonaws.com
...
Service Exposing More Than One Port
Kubernetes Services allow you to define more than one port per service definition. Let’s see how a web server service definition file may look like:
apiVersion: v1
kind: Service
metadata:
name: webserver
spec:
selector:
app: web
ports:
- name: http
port: 80
targetPort: 80
- name: https
port: 443
targetPort: 443
Notice that if you are defining more than one port in a service, you must provide a name for each port so that they are recognizable.
Kubernetes Service Without Pods?
While the traditional use of a Kubernetes Service is to abstract one or more pods behind a layer, services can do more than that. Consider the following use cases where services do not work on pods:
You need to access an API outside your cluster (examples: weather, stocks, currency rates). You have a service in another Kubernetes cluster that you need to contact. You need to shift some of your infrastructure components to Kubernetes. But, since you’re still evaluating the technology, you need it to communicate with some backend applications that are still outside the cluster. You have another service in another namespace that you need to reach. The common thing here is that the service will not be pointing to pods. It’ll be communicating with other resources inside or outside your cluster. Let’s create a service definition that will route traffic to an external IP address:
apiVersion: v1
kind: Service
metadata:
name: webserver
spec:
selector:
app: web
ports:
- name: http
port: 80
targetPort: 80
- name: https
port: 443
targetPort: 443
Here, we have a service that connects to an external NodeJS backend on port 3000. But, this definition does not have pod selectors. It doesn’t even have the external IP address of the backend! So, how will the service route traffic then?
Normally, a service uses an Endpoint object behind the scenes to map to the IP addresses of the pods that match its selector.
Service Discovery
Let’s revisit our web application example. You are writing the configuration files for Nginx and you need to specify an IP address or URL to which web server shall route backend requests. For demonstration purposes, here’s a sample Nginx configuration snippet for proxying requests:
server {
listen 80;
server_name myapp.example.com;
location /api {
proxy_pass http://??/;
}
}
The proxy_pass part here must point to the service’s IP address or DNS name to be able to reach one of the NodeJS pods. In Kubernetes, there are two ways to discover services: (1) environment variables, or (2) DNS. let’s talk about each one of them in a bit of detail.
Connectivity Methods
If you reached that far, you are able to contact your services by name. Whether you’re using environment variables or you’ve deployed a DNS, you get the service name resolved to an IP address. Now you want to be serious about it and make it accessible from outside your cluster? There are three ways to do that:
CLusterIP
The ClusterIP is the default service type. Kubernetes will assign an internal IP address to your service. This IP address is reachable only from inside the cluster. You can - optionally - set this IP in the service definition file. Think of the case when you have a DNS record that you don’t want to change and you want the name to resolve to the same IP address. You can do this by defining the clusterIP part of the service definition as follows:
apiVersion: v1
kind: Service
metadata:
name: external-backend
spec:
ports:
- protocol: TCP
port: 3000
targetPort: 3000
clusterIP: 10.96.0.1
However, you cannot just add any IP address. It must be within the service-cluster-ip-range, which is a range of IP addresses assigned to the service by the Kubernetes API server. You can get this range through a simple kubectl command as follows:
$ kubectl cluster-info dump | grep service-cluster-ip-range
You can also set the clusterIP to none, effectively creating a Headless Service.
Headless Service In Kubernetes?
As mentioned, the default behavior of Kubernetes is to assign an internal IP address to the service. Through this IP address, the service will proxy and load-balance the requests to the pods behind. If we explicitly set this IP address (clusterIP) to none, this is like telling Kubernetes “I don’t need load balancing or proxying, just connect me to the first available pod”.
Let’s consider a common use case. If you host, for example, MongoDB on a single pod, you will need a service definition on top of it to take care of the pod being restarted and acquiring a new IP address. But you don’t need any load balancing or routing. You only need the service to patch the request to the backend pod. Hence, the name: headless: a service that does have an IP.
But, what if a headless service was created and was managing more than one pod? In this case, any query to the service’s DNS name will return a list of all the pods managed by this service. The request will accept the first IP address returned. Obviously, this is not the best load-balancing algorithm if at all. The bottom line here, use a headless service when you need a single pod.
NodePort
This is one of the service types that are used when you want to enable external connectivity to your service. If you’re having four Nginx pods, the NodePort service type is going to use the IP address of any node in the cluster combined with a specific port to route traffic to those pods. The following graph will demonstrate the idea:
You can use the IP address of any node, the service will receive the request and route it to one of the pods.
A service definition file for a service of type NodePort may look like this:
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
ports:
- port: 80
nodePort: 30000
targetPort: 80
selector:
app: web
Manually allocating a port to the service is optional. If left undefined, Kubernetes will automatically assign one. It must be in the range of 30000-32767. If you are going to choose it, ensure that the port was not already used by another service. Otherwise, Kubernetes will report that the API transaction has failed.
Notice that you must always anticipate the event of a node going down and its IP address becomes no longer reachable. The best practice here is to place a load balancer above your nodes.
LoadBalancer
his service type works when you are using a cloud provider to host your Kubernetes cluster. When you choose LoadBalancer as the service type, the cluster will contact the cloud provider and create a load balancer. Traffic arriving at this load balancer will be forwarded to the backend pods. The specifics of this process is dependent on how each provider implements its load balancing technology.
Different cloud providers handle load balancer provisioning differently. For example, some providers allow you to assign an IP address to the component, while others choose to assign short-lived addresses that constantly change. Kubernetes was designed to be highly portable. You can add loadBalancerIP to the service definition file. If the provider supports it, it will be implemented. Otherwise, it will be ignored. Let’s have a sample service definition that uses LoadBalancer as its type:
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: LoadBalancer
loadBalancerIP: 78.11.24.19
selector:
app: web
ports:
- protocol: TCP
port: 80
targetPort: 80
One of the main differences between the LoadBalancer and the NodePort service types is that in the latter you get to choose your own load balancing layer. You are not bound to the cloud provider’s implementation
5 - Deploying Your First Nginx Deployment
Deployment 101
We looked at ReplicaSets earlier. However, ReplicaSet have one major drawback: once you select the pods that are managed by a ReplicaSet, you cannot change their pod templates.
For example, if you are using a ReplicaSet to deploy four pods with NodeJS running and you want to change the NodeJS image to a newer version, you need to delete the ReplicaSet and recreate it. Restarting the pods causes downtime till the images are available and the pods are running again.
A Deployment resource uses a ReplicaSet to manage the pods. However, it handles updating them in a controlled way. Let’s dig deeper into Deployment Controllers and patterns.
Step #1. Creating Your First Deployment
The following Deployment definition deploys four pods with nginx as their hosted application:
$ kubectl create -f nginx-dep.yaml
deployment.apps/nginx-deployment created
Checking the list of application deployment
To list your deployments use the get deployments command:
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 63s
$ kubectl describe deploy
Name: nginx-deployment
Namespace: default
CreationTimestamp: Mon, 30 Dec 2019 07:10:33 +0000
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 0 available | 2 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.7.9
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
Progressing True ReplicaSetUpdated
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-6dd86d77d (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 90s deployment-controller Scaled up replica set nginx-deployment-6dd86d77d to 2
We should have 1 Pod. If not, run the command again. This shows:
The DESIRED state is showing the configured number of replicas
The CURRENT state show how many replicas are running now
The UP-TO-DATE is the number of replicas that were updated to match the desired (configured) state
The AVAILABLE state shows how many replicas are actually AVAILABLE to the users
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 2m57s
$ kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-deployment-6dd86d77d-84fwp 1/1 Running 0 3m44s
nginx-deployment-6dd86d77d-xnrqp 1/1 Running 0 3m44s
Step #2. Scale up/down application deployment
Now let’s scale the Deployment to 4 replicas. We are going to use the kubectl scale command, followed by the deployment type, name and desired number of instances:
$ kubectl scale deployments/nginx-deployment --replicas=4
deployment.extensions/nginx-deployment scaled
The change was applied, and we have 4 instances of the application available. Next, let’s check if the number of Pods changed:
Now There should be 4 pods running in the cluster
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 4/4 4 4 4m
There are 4 Pods now, with different IP addresses. The change was registered in the Deployment events log. To check that, use the describe command:
$ kubectl describe deployments/nginx-deployment
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sat, 30 Nov 2019 20:04:34 +0530
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.7.9
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-6dd86d77d (4/4 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 6m12s deployment-controller Scaled up replica set nginx-deployment-6dd86d77d to 2
Normal ScalingReplicaSet 3m6s deployment-controller Scaled up replica set nginx-deployment-6dd86d77d to 4
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6dd86d77d-b4v7k 1/1 Running 0 4m32s 10.1.0.237 docker-desktop <none> <none>
nginx-deployment-6dd86d77d-bnc5m 1/1 Running 0 4m32s 10.1.0.236 docker-desktop <none> <none>
nginx-deployment-6dd86d77d-bs6jr 1/1 Running 0 86s 10.1.0.239 docker-desktop <none> <none>
nginx-deployment-6dd86d77d-wbdzv 1/1 Running 0 86s 10.1.0.238 docker-desktop <none> <none>
You can also view in the output of this command that there are 4 replicas now.
Scaling the service to 2 Replicas
To scale down the Service to 2 replicas, run again the scale command:
$ kubectl scale deployments/nginx-deployment --replicas=2
deployment.extensions/nginx-deployment scaled
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 7m23s
Step #3. Perform rolling updates to application deployment
So far, everything our Deployment did is no different than a typical ReplicaSet. The real power of a Deployment lies in its ability to update the pod templates without causing application outage.
Let’s say that you have finished testing the nginx 1.7.9 , and you are ready to use it in production. The current pods are using the older nginx version . The following command changes the deployment pod template to use the new image:
To update the image of the application to new version, use the set image command, followed by the deployment name and the new image version:
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 7m23s
$ kubectl describe pods
Name: nginx-deployment-6dd86d77d-b4v7k
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: docker-desktop/192.168.65.3
Start Time: Sat, 30 Nov 2019 20:04:34 +0530
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.1.0.237
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://2c739cf9fe4dac53a4cc5c6097207da0c5edc2183f1f36f9f3e5c7057f85da43
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 30 Nov 2019 20:05:28 +0530
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-ds5tg (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-ds5tg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-ds5tg
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned default/nginx-deployment-6dd86d77d-b4v7k to docker-desktop
Normal Pulling 10m kubelet, docker-desktop Pulling image "nginx:1.7.9"
Normal Pulled 9m17s kubelet, docker-desktop Successfully pulled image "nginx:1.7.9"
Normal Created 9m17s kubelet, docker-desktop Created container nginx
Normal Started 9m17s kubelet, docker-desktop Started container nginx
Name: nginx-deployment-6dd86d77d-bnc5m
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: docker-desktop/192.168.65.3
Start Time: Sat, 30 Nov 2019 20:04:34 +0530
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.1.0.236
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://12ab35cbf4fdf78997b106b5eb27135f2fc37c890e723fee44ac820ba1b1fd75
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 30 Nov 2019 20:05:23 +0530
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-ds5tg (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-ds5tg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-ds5tg
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned default/nginx-deployment-6dd86d77d-bnc5m to docker-desktop
Normal Pulling 10m kubelet, docker-desktop Pulling image "nginx:1.7.9"
Normal Pulled 9m22s kubelet, docker-desktop Successfully pulled image "nginx:1.7.9"
Normal Created 9m22s kubelet, docker-desktop Created container nginx
Normal Started 9m22s kubelet, docker-desktop Started container nginx
The command notified the Deployment to use a different image for your app and initiated a rolling update. Check the status of the new Pods, and view the old one terminating with the get pods command:
$ kubectl set image deployments/nginx-deployment nginx=nginx:1.9.1
deployment.extensions/nginx-deployment image updated
Checking description of pod again
$ kubectl describe pods
Name: nginx-deployment-6dd86d77d-b4v7k
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: docker-desktop/192.168.65.3
Start Time: Sat, 30 Nov 2019 20:04:34 +0530
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.1.0.237
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://2c739cf9fe4dac53a4cc5c6097207da0c5edc2183f1f36f9f3e5c7057f85da43
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 30 Nov 2019 20:05:28 +0530
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-ds5tg (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-ds5tg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-ds5tg
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 16m default-scheduler Successfully assigned default/nginx-deployment-6dd86d77d-b4v7k to docker-desktop
Normal Pulling 16m kubelet, docker-desktop Pulling image "nginx:1.7.9"
Normal Pulled 15m kubelet, docker-desktop Successfully pulled image "nginx:1.7.9"
Normal Created 15m kubelet, docker-desktop Created container nginx
Normal Started 15m kubelet, docker-desktop Started container nginx
Name: nginx-deployment-6dd86d77d-bnc5m
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: docker-desktop/192.168.65.3
Start Time: Sat, 30 Nov 2019 20:04:34 +0530
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.1.0.236
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://12ab35cbf4fdf78997b106b5eb27135f2fc37c890e723fee44ac820ba1b1fd75
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sat, 30 Nov 2019 20:05:23 +0530
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-ds5tg (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-ds5tg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-ds5tg
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 16m default-scheduler Successfully assigned default/nginx-deployment-6dd86d77d-bnc5m to docker-desktop
Normal Pulling 16m kubelet, docker-desktop Pulling image "nginx:1.7.9"
Normal Pulled 15m kubelet, docker-desktop Successfully pulled image "nginx:1.7.9"
Normal Created 15m kubelet, docker-desktop Created container nginx
Normal Started 15m kubelet, docker-desktop Started container nginx
Name: nginx-deployment-784b7cc96d-kxc68
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: docker-desktop/192.168.65.3
Start Time: Sat, 30 Nov 2019 20:20:04 +0530
Labels: app=nginx
pod-template-hash=784b7cc96d
Annotations: <none>
Status: Pending
IP:
Controlled By: ReplicaSet/nginx-deployment-784b7cc96d
Containers:
nginx:
Container ID:
Image: nginx:1.9.1
Image ID:
Port: 80/TCP
Host Port: 0/TCP
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-ds5tg (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-ds5tg:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-ds5tg
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 36s default-scheduler Successfully assigned default/nginx-deployment-784b7cc96d-kxc68 to docker-desktop
Normal Pulling 35s kubelet, docker-desktop Pulling image "nginx:1.9.1"
Step #4. Rollback updates to application deployment
The rollout command reverted the deployment to the previous known state. Updates are versioned and you can revert to any previously know state of a Deployment. List again the Pods:
$ kubectl rollout undo deployments/nginx-deployment
deployment.extensions/nginx-deployment rolled back
$ kubectl rollout status deployments/nginx-deployment
deployment "nginx-deployment" successfully rolled out
After the rollout succeeds, you may want to get the Deployment.
The output shows the update progress until all the pods use the new container image.
The algorithm that Kubernetes Deployments use when deciding how to roll updates is to keep at least 25% of the pods running. Accordingly, it doesn’t kill old pods unless a sufficient number of new ones are up. In the same sense, it does not create new pods until enough pods are no longer running. Through this algorithm, the application is always available during updates.
You can use the following command to determine the update strategy that the Deployment is using:
$ kubectl describe deployments | grep Strategy
StrategyType: RollingUpdate
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Step #5. Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete service nginx-deployment
$ kubectl delete deployment nginx-deployment
6 - Deploying Your First DaemonSet
What is a DaemonSet?
Say, you want to run a process on all the nodes of the cluster. One of the easy solution could be running cron job that runs on machine boot or reboot. Also, alternatively one can use the /etc/init.local file to ensure that a specific process or command gets executed as soon as the server gets started. Though it looks to be viable solution, using the node itself to control the daemons that run on it (especially within a Kubernetes cluster) suffers some drawbacks:
- We need the process to remain running on the node as long as it is part of the cluster. It should be terminated when the node is evicted.
- The process may need a particular runtime environment that may or may not be available on the node (for example, a specific JDK version, a required kernel library, a specific Linux distro…etc.). So, the process should run inside a container. Kubernetes uses Pods to run containers. This daemon should be aware that it is running within Kubernetes. Hence, it has access to other pods in the cluster and is part of the network.
Enter DaemonSets
DaemonSets are used to ensure that some or all of your K8S nodes run a copy of a pod, which allows you to run a daemon on every node.
When you add a new node to the cluster, a pod gets added to match the nodes. Similarly, when you remove a node from your cluster, the pod is put into the trash. Deleting a DaemonSet cleans up the pods that it previously created.
A Daemonset is another controller that manages pods like Deployments, ReplicaSets, and StatefulSets. It was created for one particular purpose: ensuring that the pods it manages to run on all the cluster nodes. As soon as a node joins the cluster, the DaemonSet ensures that it has the necessary pods running on it. When the node leaves the cluster, those pods are garbage collected.
DaemonSets are used in Kubernetes when you need to run one or more pods on all (or a subset of) the nodes in a cluster. The typical use case for a DaemonSet is logging and monitoring for the hosts. For example, a node needs a service (daemon) that collects health or log data and pushes them to a central system or database (like ELK stack). DaemonSets can be deployed to specific nodes either by the nodes’ user-defined labels or using values provided by Kubernetes like the node hostname.
Why use DaemonSets?
-
Now that we understand DaemonSets, here are some examples of why and how to use it:
-
To run a daemon for cluster storage on each node, such as: - glusterd - ceph
-
To run a daemon for logs collection on each node, such as: - fluentd - logstash
-
To run a daemon for node monitoring on ever note, such as: - Prometheus Node Exporter - collectd - Datadog agent
-
As your use case gets more complex, you can deploy multiple DaemonSets for one kind of daemon, using a variety of flags or memory and CPU requests for various hardware types.
Creating your first DeamonSet Deployment
$ kubectl apply -f daemonset.yml
The other way to do this:
$ kubectl create -f daemonset.yml --record
The –record flag will track changes made through each revision.
Getting the basic details about daemonsets:
$ kubectl get daemonsets/prometheus-daemonset
Further Details
$ kubectl describe daemonset/prometheus-daemonset
$ kubectl describe daemonset/prometheus-daemonset
Name: prometheus-daemonset
Selector: name=prometheus-exporter,tier=monitoring
Node-Selector: <none>
Labels: name=prometheus-exporter
tier=monitoring
Annotations: deprecated.daemonset.template.generation: 1
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"extensions/v1beta1","kind":"DaemonSet","metadata":{"annotations":{},"name":"prometheus-daemonset","namespace":"default"},"s...
Desired Number of Nodes Scheduled: 1Current Number of Nodes Scheduled: 1
Number of Nodes Scheduled with Up-to-date Pods: 1
Number of Nodes Scheduled with Available Pods: 1
Number of Nodes Misscheduled: 0
Pods Status: 1 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: name=prometheus-exporter
tier=monitoring
Containers:
prometheus:
Image: prom/node-exporter
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 3m21s daemonset-controller Created pod: prometheus-daemonset-nsjwx
Getting pods in daemonset:
$ kubectl get pods -lname=prometheus-exporter
$ kubectl get pods -lname=prometheus-exporterNAME
READY STATUS RESTARTS AGE
prometheus-daemonset-nsjwx 1/1 Running 0 4m12s
Delete a daemonset:
$ kubectl delete -f daemonset.yml
Restrict DaemonSets To Run On Specific Nodes
By default, a DaemonSet schedules its pods on all the cluster nodes. But sometimes you may need to run specific processes on specific nodes. For example, nodes that host database pods need different monitoring or logging rules. DaemonSets allow you to select which nodes you want to run the pods on. You can do this by using nodeSelector. With nodeSelector, you can select nodes by their labels the same way you do with pods. However, Kubernetes also allows you to select nodes based on some already-defined node properties. For example, kubernetes.io/hostname matches the node name. So, our example cluster has two nodes. We can modify the DaemonSet definition to run only on the first node. Lets’ first get the node names:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready master 17m v1.18.0
node2 Ready <none> 17m v1.18.0
You need to add the below entry in the above YAML file:
nodeSelector:
kubernetes.io/hostname: node1
How To Reach a DaemonSet Pod
-
There are several design patterns DaemonSet-pods communication in the cluster:
-
The Push pattern: pods do not receive traffic. Instead, they push data to other services like ElasticSearch, for example.
-
NodeIP and known port pattern: in this design, pods use the hostPort to acquire the node’s IP address. Clients can use the node IP and the known port (for example, port 80 if the DaemonSet has a web server) to connect to the pod.
-
DNS pattern: create a Headless Service that selects the DaemonSet pods. Use Endpoints to discover DaemonSet pods.
-
Service pattern: create a traditional service that selects the DaemonSet pods. Use NodePort to expose the pods using a random port. The drawback of this approach is that there is no way to choose a specific pod.
7 - Deploying Your First Nginx ReplicaSet
Kubernetes ReplicaSet
-
ReplicaSets are Kubernetes controllers that are used to maintain the number and running state of pods.
-
It uses labels to select pods that it should be managing.
-
A pod must labeled with a matching label to the ReplicaSet selector, and it must not be already owned by another controller so that the ReplicaSet can acquire it.
-
Pods can be isolated from a ReplicaSet by simply changing their labels so that they no longer match the ReplicaSet’s selector.
-
ReplicaSets can be deleted with or without deleting their dependent pods.
-
You can easily control the number of replicas (pods) the ReplicaSet should maintain through the command line or by directly editing the ReplicaSet configuration on the fly.
-
You can also configure the ReplicaSet to autoscale based on the amount of CPU load the node is experiencing.
-
You may have read about ReplicationControllers in older Kubernetes documentation, articles or books. ReplicaSets are the successors of ReplicationControllers. They are recommended to be used instead of ReplicationControllers as they provide more features.
-
A Kubernetes pod serves as a deployment unit for the cluster.
-
It may contain one or more containers.
-
However, containers (and accordingly, pods) are short-lived entities.
-
A container hosting a PHP application, for example may experience an unhandled code exception causing the process to fail, effectively crashing the container. Of course, the perfect solution for such a case is to refactor the code to properly handle exceptions.
-
But, till that happens we need to keep the application running and the business going. In other words, we need to restart the pod whenever it fails.
-
In parallel, developers are monitoring, investigating and fixing any errors that make it crash.
-
At some point, a new version of the pod is deployed, monitored and maintained. It’s an ongoing process that is part of the DevOps practice.
Another requirement is to keep a predefined number of pods running. If more pods are up, the additional ones are terminated. Similarly, of one or more pods failed, new pods are activated until the desired count is reached.
A Kubernetes ReplicaSet resource was designed to address both of those requirements. It creates and maintains a specific number of similar pods (replicas).
Under this lab, we’ll discuss how we can define a ReplicaSet and what are the different options that can be used for fine-tuning it.
How Does ReplicaSet Manage Pods?
-
In order for a ReplicaSet to work, it needs to know which pods it will manage so that it can restart the failing ones or kill the unneeded.
-
It also requires to understand how to create new pods from scratch in case it needs to spawn new ones.
-
A ReplicaSet uses labels to match the pods that it will manage. It also needs to check whether the target pod is already managed by another controller (like a Deployment or another ReplicaSet). So, for example if we need our ReplicaSet to manage all pods with the label role=webserver, the controller will search for any pod with that label. It will also examine the ownerReferences field of the pod’s metadata to determine whether or not this pod is already owned by another controller. If it isn’t, the ReplicaSet will start controlling it. Subsequently, the ownerReferences field of the target pods will be updated to reflect the new owner’s data.
To be able to create new pods if necessary, the ReplicaSet definition includes a template part containing the definition for new pods.
Creating Your First ReplicaSet
$ kubectl apply -f nginx_replicaset.yaml
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
web 4 4 4 2m
A Peep into the ReplicaSet definition file
Let’s examine the definition file that was used to create our ReplicaSet:
- The apiVersion for this object is currently app/v1
- The kind of this object is ReplicaSet
- In the metadata part, we define the name by which we can refer to this ReplicaSet. We also define a number of labels through which we can identify it.
- The spec part is mandatory in the ReplicaSet object. It defines:
- The number of replicas this controller should maintain. It default to 1 if it was not specified.
- The selection criteria by which the ReplicaSet will choose its pods. Be careful not to use a label that is already in use by another controller. Otherwise, another ReplicaSet may acquire the pod(s) first. Also notice that the labels defined in the pod template (spec.template.metadata.label) cannot be different than those defined in the matchLabels part (spec.selector).
- The pod template is used to create (or recreate) new pods. It has its own metadata, and spec where the containers are specified. You can refer to our article for more information about pods.
Is Our ReplicaSet the Owner of Those Pods?
OK, so we do have four pods running, and our ReplicaSet reports that it is controlling four pods. In a busier environment, you may want to verify that a particular pod is actually managed by this ReplicaSet and not by another controller. By simply querying the pod, you can get this info:
$ kubectl get pods web-6n9cj -o yaml | grep -A 5 owner
The first part of the command will get all the pod information, which may be too verbose. Using grep with the -A flag (it takes a number and prints that number of lines after the match) will get us the required information as in the example:
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: web
Removing a Pod From a ReplicaSet
You can remove (not delete) a pod that is managed by a ReplicaSet by simply changing its label. Let’s isolate one of the pods created in our previous example:
$ kubectl edit pods web-44cjb
Then, once the YAML file is opened, change the pod label to be role=isolated or anything different than role=web. In a few moments, run kubectl get pods. You will notice that we have five pods now. That’s because the ReplicaSet dutifully created a new pod to reach the desired number of four pods. The isolated one is still running, but it is no longer managed by the ReplicaSet.
Scaling the Replicas to 5
$ kubectl scale --replicas=5 -f nginx_replicaset.yaml
Scaling and Autoscaling ReplicaSets
You can easily change the number of pods a particular ReplicaSet manages in one of two ways:
-
Edit the controllers configuration by using kubectl edit rs ReplicaSet_name and change the replicas count up or down as you desire.
-
Use kubectl directly. For example, kubectl scale –replicas=2 rs/web. Here, I’m scaling down the ReplicaSet used in the article’s example to manage two pods instead of four. The ReplicaSet will get rid of two pods to maintain the desired count. If you followed the previous section, you may find that the number of running pods is three instead of two; as we isolated one of the pods so it is no longer managed by our ReplicaSet.
$ kubectl autoscale rs web --max=5
This will use the Horizontal Pod Autoscaler (HPA) with the ReplicaSet to increase the number of pods when the CPU load gets higher, but it should not exceed five pods. When the load decreases, it cannot have less than the number of pods specified before (two in our example).
Best Practices
The recommended practice is to always use the ReplicaSet’s template for creating and managing pods. However, because of the way ReplicaSets work, if you create a bare pod (not owned by any controller) with a label that matches the ReplicaSet selector, the controller will automatically adopt it. This has a number of undesirable consequences. Let’s have a quick lab to demonstrate them.
Deploy a pod by using a definition file like the following:
apiVersion: v1
kind: Pod
metadata:
name: orphan
labels:
role: web
spec:
containers:
- name: orphan
image: httpd
It looks a lot like the other pods, but it is using Apache (httpd) instead of Nginx for an image. Using kubectl, we can apply this definition like:
$ kubectl apply -f orphan.yaml
Give it a few moments for the image to get pulled and the container is spawned then run kubectl get pods. You should see an output that looks like the following:
NAME READY STATUS RESTARTS AGE
orphan 0/1 Terminating 0 1m
web-6n9cj 1/1 Running 0 25m
web-7kqbm 1/1 Running 0 25m
web-9src7 1/1 Running 0 25m
web-fvxzf 1/1 Running 0 25m
The pod is being terminated by the ReplicaSet because, by adopting it, the controller has more pods than it was configured to handle. So, it is killing the excess one.
Another scenario where the ReplicaSet won’t terminate the bare pod is that the latter gets created before the ReplicaSet does. To demonstrate this case, let’s destroy our ReplicaSet:
$ kubectl delete -f nginx_replicaset.yaml
Now, let’s create it again (our orphan pod is still running):
$ kubectl apply -f nginx_replicaset.yaml
Let’s have a look at our pods status by running kubectl get pods. The output should resemble the following:
orphan 1/1 Running 0 29s
web-44cjb 1/1 Running 0 12s
web-hcr9j 1/1 Running 0 12s
web-kc4r9 1/1 Running 0 12s
The situation now is that we’re having three pods running Nginx, and one pod running Apache (the httpd image). As far as the ReplicaSet is concerned, it is handling four pods (the desired number), and their labels match its selector. But what if the Apache pod went down?
Let’s do just that:
$ kubectl delete pods orphan
Now, let’s see how the ReplicaSet responded to this event:
$ kubectl get pods
The output should be something like:
NAME READY STATUS RESTARTS AGE
web-44cjb 1/1 Running 0 24s
web-5kjwx 0/1 ContainerCreating 0 3s
web-hcr9j 1/1 Running 0 24s
web-kc4r9 1/1 Running 0 24s
The ReplicaSet is doing what is was programmed to: creating a new pod to reach the desired state using the template that was added in its definition. Obviously, it is creating a new Nginx container instead of the Apache one that was deleted.
So, although the ReplicaSet is supposed to maintain the state of the pods it manages, it failed to respawn the Apache web server. It replaced it with an Nginx one.
The bottom line: you should never create a pod with a label that matches the selector of a controller unless its template matches the pod definition. The more-encouraged procedure is to always use a controller like a ReplicaSet or, even better, a Deployment to create and maintain your pods.
Deleting Replicaset
$ kubectl delete rs ReplicaSet_name
Alternatively, you can also use the file that was used to create the resource (and possibly, other resource definitions as well) to delete all the resources defined in the file as follows:
$ kubectl delete -f definition_file.yaml
The above commands will delete the ReplicaSet and all the pods that it manges. But sometimes you may want to just delete the ReplicaSet resource, keeping the pods unowned (orphaned). Maybe you want to manually delete the pods and you don’t want the ReplicaSet to restart them. This can be done using the following command:
$ kubectl delete rs ReplicaSet_name --cascade=false
If you run kubectl get rs now you should see that there are no ReplicaSets there. Yet if you run kubectl get pods, you should see all the pods that were managed by the destroyed ReplicaSet still running.
The only way to get those pods managed by a ReplicaSet again is to create this ReplicaSet with the same selector and pod template as the previous one. If you need a different pod template, you should consider using a Deployment instead, which will handle replacing pods in a controlled way.
8 - Understand Kubernetes Scheduling
What is Kubernetes Scheduling?
- The Kubernetes Scheduler is a core component of Kubernetes: After a user or a controller creates a Pod, the Kubernetes Scheduler, monitoring the Object Store for unassigned Pods, will assign the Pod to a Node. Then, the Kubelet, monitoring the Object Store for assigned Pods, will execute the Pod.
what is the scheduler for?
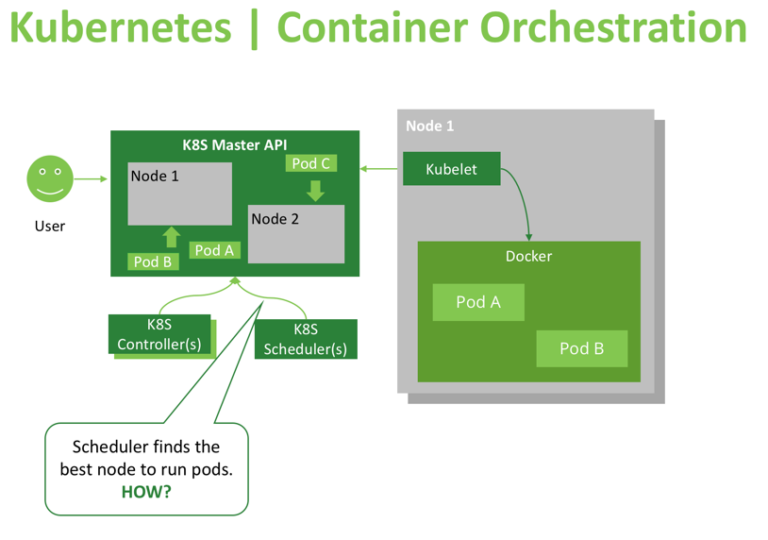
The Kubernetes scheduler is in charge of scheduling pods onto nodes. Basically it works like this:
- You create a pod
- The scheduler notices that the new pod you created doesn’t have a node assigned to it
- The scheduler assigns a node to the pod
It’s not responsible for actually running the pod – that’s the kubelet’s job. So it basically just needs to make sure every pod has a node assigned to it. Easy, right?
Kubernetes in general has this idea of a “controller”. A controller’s job is to:
- look at the state of the system
- notice ways in which the actual state does not match the desired state (like “this pod needs to be assigned a node”)
- repeat
The scheduler is a kind of controller. There are lots of different controllers and they all have different jobs and operate independently.
How Kubernetes Selects The Right node?
What is node affinity ?
- In simple words this allows you to tell Kubernetes to schedule pods only to specific subsets of nodes.
- The initial node affinity mechanism in early versions of Kubernetes was the nodeSelector field in the pod specification. The node had to include all the labels specified in that field to be eligible to become the target for the pod.
nodeSelector
Steps
$ kubectl label nodes node2 mynode=worker-1
$ kubectl apply -f pod-nginx.yaml
- We have label on the node with node name,in this case i have given node2 as mynode=worker-1 label.
Viewing Your Pods
$ kubectl get pods --output=wide
$ kubectl describe po nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node2/192.168.0.17
Start Time: Mon, 30 Dec 2019 16:40:53 +0000
Labels: env=test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"env":"test"},"name":"nginx","namespace":"default"},"spec":{"contai...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: mynode=worker-1
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 3s kubelet, node2 Pulling image "nginx"
[node1 Scheduler101]$
- You can check in above output Node-Selectors: mynode=worker-1
Deleting the Pod
$ kubectl delete -f pod-nginx.yaml
pod "nginx" deleted
Node affinity
-
Node affinity is conceptually similar to nodeSelector – it allows you to constrain which nodes your pod is eligible to be scheduled on, based on labels on the node.
-
There are currently two types of node affinity.
- requiredDuringSchedulingIgnoredDuringExecution (Preferred during scheduling, ignored during execution; we are also known as “hard” requirements)
- preferredDuringSchedulingIgnoredDuringExecution (Required during scheduling, ignored during execution; we are also known as “soft” requirements)
Steps
$ kubectl label nodes node2 mynode=worker-1
$ kubectl label nodes node3 mynode=worker-3
$ kubectl apply -f pod-with-node-affinity.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
with-node-affinity 1/1 Running 0 9m46s 10.44.0.1 kube-slave1 <none> <none>
$ kubectl describe po
Name: with-node-affinity
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:28:33 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"with-node-affinity","namespace":"default"},"spec":{"affinity":{"nodeA...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 26s default-scheduler Successfully assigned default/with-node-affinity to node3
Normal Pulling 22s kubelet, node3 Pulling image "nginx"
Normal Pulled 20s kubelet, node3 Successfully pulled image "nginx"
Normal Created 2s kubelet, node3 Created container nginx
Normal Started 0s kubelet, node3 Started container nginx
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-with-node-affinity.yaml
Anti-Node Affinity ?
- Some scenarios require that you don’t use one or more nodes except for particular pods. Think of the nodes that host your monitoring application.
- Those nodes shouldn’t have many resources due to the nature of their role. Thus, if other pods than those which have the monitoring app are scheduled to those nodes, they hurt monitoring and also degrades the application they are hosting.
- In such a case, you need to use node anti-affinity to keep pods away from a set of nodes.
Steps
$ kubectl label nodes node2 mynode=worker-1
$ kubectl label nodes node3 mynode=worker-3
$ kubectl apply -f pod-anti-node-affinity.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 2m37s 10.44.0.1 node2 <none> <none>
Get nodes label detail
$ kubectl get nodes --show-labels | grep mynode
node2 Ready <none> 166m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux,mynode=worker-1,role=dev
node3 Ready <none> 165m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node3,kubernetes.io/os=linux,mynode=worker-3
Get pod describe
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node2/192.168.0.17
Start Time: Mon, 30 Dec 2019 19:02:46 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"nginx","namespace":"default"},"spec":{"affinity":{"nodeAffinity":{"re...
Status: Running
IP: 10.44.0.1
Containers:
nginx:
Container ID: docker://2bdc20d79c360e1cd857eeb9bbb9424c726b2133e78f25bf4587e0befe3fbcc7
Image: nginx
Image ID: docker-pullable://nginx@sha256:b2d89d0a210398b4d1120b3e3a7672c16a4ba09c2c4a0395f18b9f7999b768f2
Port: <none>
Host Port: <none>
State: Running
Started: Mon, 30 Dec 2019 19:03:07 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 60s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 56s kubelet, node2 Pulling image "nginx"
Normal Pulled 54s kubelet, node2 Successfully pulled image "nginx"
Normal Created 40s kubelet, node2 Created container nginx
Normal Started 39s kubelet, node2 Started container nginx
- Adding another key to the matchExpressions with the operator NotIn will avoid scheduling the nginx pods on any node labelled worker-1.
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-anti-node-affinity.yaml
What is Node taints and tolerations ?
-
This Kubernetes feature allows users to mark a node (taint the node) so that no pods can be scheduled to it, unless a pod explicitly tolerates the taint.
-
When you taint a node, it is automatically excluded from pod scheduling. When the schedule runs the predicate tests on a tainted node, they’ll fail unless the pod has toleration for that node.
-
Like last monitoring example: Let assume new member joins the development team, writes a Deployment for her application, but forgets to exclude the monitoring nodes from the target nodes? Kubernetes administrators need a way to repel pods from nodes without having to modify every pod definition.
Steps
$ kubectl label nodes node2 role=dev
$ kubectl label nodes node3 role=dev
$ kubectl taint nodes node2 role=dev:NoSchedule
node/node2 tainted
$ kubectl apply -f pod-taint-node.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
Get nodes label detail
[node1 Scheduler101]$ kubectl get nodes --show-labels|grep mynode |grep role
node2 Ready <none> 175m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux,mynode=worker-1,role=dev
node3 Ready <none> 175m v1.14.9 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node3,kubernetes.io/os=linux,mynode=worker-3,role=dev
Get pod describe
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:13:45 +0000
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"nginx","namespace":"default"},"spec":{"affinity":{"nodeAffinity":{"re...
Status: Running
IP: 10.36.0.1
Containers:
nginx:
Container ID: docker://57d032f4358be89e2fcad7536992b175503565af82ce4f66f4773f6feaf58356
Image: nginx
Image ID: docker-pullable://nginx@sha256:b2d89d0a210398b4d1120b3e3a7672c16a4ba09c2c4a0395f18b9f7999b768f2
Port: <none>
Host Port: <none>
State: Running
Started: Mon, 30 Dec 2019 19:14:45 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 105s default-scheduler Successfully assigned default/nginx to node3
Normal Pulling 101s kubelet, node3 Pulling image "nginx"
Normal Pulled 57s kubelet, node3 Successfully pulled image "nginx"
Normal Created 47s kubelet, node3 Created container nginx
Normal Started 45s kubelet, node3 Started container nginx
- Deployed pod on node3.
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-tain-node.yaml
Tolerations
- A toleration is a way of ignoring a taint during scheduling. Tolerations aren’t applied to nodes, but rather the pods. So, in the example above, if we apply a toleration to the PodSpec, we could “tolerate” the slow disks on that node and still use it.
Steps
$ kubectl apply -f pod-tolerations-node.yaml
Viewing Your Pods
$ kubectl get pods --output=wide
Which Node Is This Pod Running On?
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node3/192.168.0.16
Start Time: Mon, 30 Dec 2019 19:20:35 +0000
Labels: env=test
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"env":"test"},"name":"nginx","namespace":"default"},"spec":{"contai...
Status: Pending
IP:
Containers:
nginx:
Container ID:
Image: nginx:1.7.9
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-qpgxq (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-qpgxq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-qpgxq
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
role=dev:NoSchedule
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4s default-scheduler Successfully assigned default/nginx to node3
Normal Pulling 1s kubelet, node3 Pulling image "nginx:1.7.9
Step Cleanup
Finally you can clean up the resources you created in your cluster:
$ kubectl delete -f pod-tolerations-node.yaml
- An important thing to notice, though, is that tolerations may enable a tainted node to accept a pod but it does not guarantee that this pod runs on that specific node.
- In other words, the tainted node will be considered as one of the candidates for running our pod. However, if another node has a higher priority score, it will be chosen instead. For situations like this, you need to combine the toleration with nodeSelector or node affinity parameters.
9 - Deploying Your First Ingress Deployment
What is an Ingress?
-
In Kubernetes, an Ingress is an object that allows access to your Kubernetes services from outside the Kubernetes cluster. You configure access by creating a collection of rules that define which inbound connections reach which services.
-
This lets you consolidate your routing rules into a single resource. For example, you might want to send requests to example.com/api/v1/ to an api-v1 service, and requests to example.com/api/v2/ to the api-v2 service. With an Ingress, you can easily set this up without creating a bunch of LoadBalancers or exposing each service on the Node.
Kubernetes Ingress vs LoadBalancer vs NodePort
These options all do the same thing. They let you expose a service to external network requests. They let you send a request from outside the Kubernetes cluster to a service inside the cluster.
NodePort
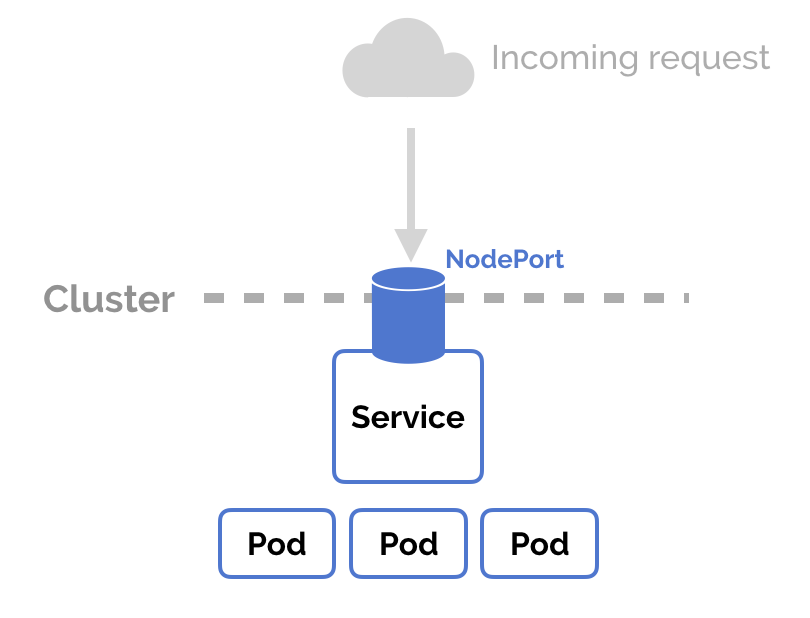
-
NodePort is a configuration setting you declare in a service’s YAML. Set the service spec’s type to NodePort. Then, Kubernetes will allocate a specific port on each Node to that service, and any request to your cluster on that port gets forwarded to the service.
-
This is cool and easy, it’s just not super robust. You don’t know what port your service is going to be allocated, and the port might get re-allocated at some point.
LoadBalancer
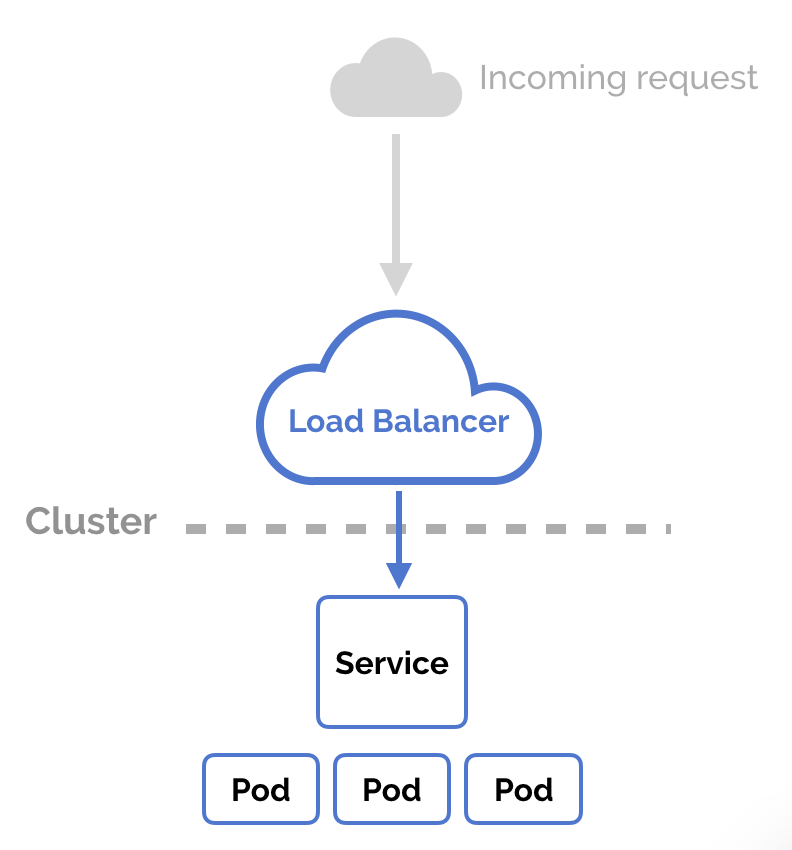
-
You can set a service to be of type LoadBalancer the same way you’d set NodePort— specify the type property in the service’s YAML. There needs to be some external load balancer functionality in the cluster, typically implemented by a cloud provider.
-
This is typically heavily dependent on the cloud provider—GKE creates a Network Load Balancer with an IP address that you can use to access your service.
-
Every time you want to expose a service to the outside world, you have to create a new LoadBalancer and get an IP address.
Ingress
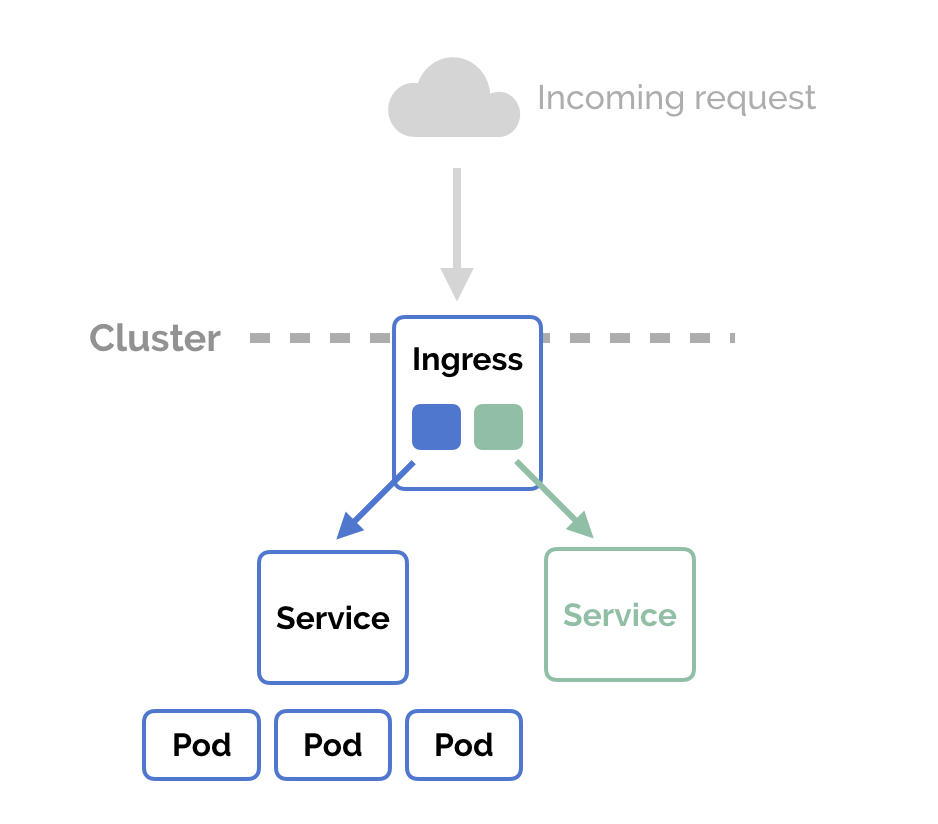
-
NodePort and LoadBalancer let you expose a service by specifying that value in the service’s type. Ingress, on the other hand, is a completely independent resource to your service. You declare, create and destroy it separately to your services.
-
This makes it decoupled and isolated from the services you want to expose. It also helps you to consolidate routing rules into one place.
-
The one downside is that you need to configure an Ingress Controller for your cluster. But that’s pretty easy—in this example, we’ll use the Nginx Ingress Controller.
How to Use Nginx Ingress Controller
- Start by creating the “mandatory” resources for Nginx Ingress in your cluster.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml
- Then, enable the ingress add-on for Minikube
minikube addons enable ingress
- Or, if you’re using Docker for Mac to run Kubernetes instead of Minikube.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/provider/cloud-generic.yaml
- Check that it’s all set up correctly.
kubectl get pods --all-namespaces -l app=ingress-nginx
Creating a Kubernetes Ingress
- First, let’s create two services to demonstrate how the Ingress routes our request. We’ll run two web applications that output a slightly different response.
$ kubectl apply -f apple.yaml
$ kubectl apply -f banana.yaml
- Create the Ingress in the cluster
kubectl create -f ingress.yaml
Perfect! Let’s check that it’s working. If you’re using Minikube, you might need to replace localhost with minikube IP.
$ curl -kL http://localhost/apple
apple
$ curl -kL http://localhost/banana
banana
$ curl -kL http://localhost/notfound
default backend - 404
Ingress Controllers and Ingress Resources
-
Kubernetes supports a high level abstraction called Ingress, which allows simple host or URL based HTTP routing. An ingress is a core concept (in beta) of Kubernetes, but is always implemented by a third party proxy. These implementations are known as ingress controllers. An ingress controller is responsible for reading the Ingress Resource information and processing that data accordingly. Different ingress controllers have extended the specification in different ways to support additional use cases.
-
Ingress is tightly integrated into Kubernetes, meaning that your existing workflows around kubectl will likely extend nicely to managing ingress. Note that an ingress controller typically doesn’t eliminate the need for an external load balancer — the ingress controller simply adds an additional layer of routing and control behind the load balancer.